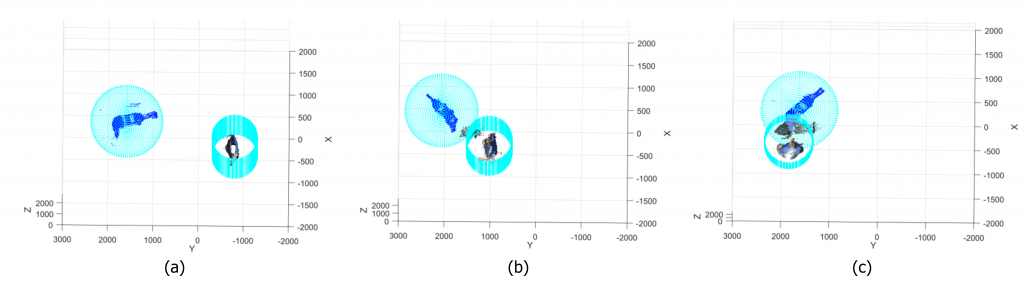
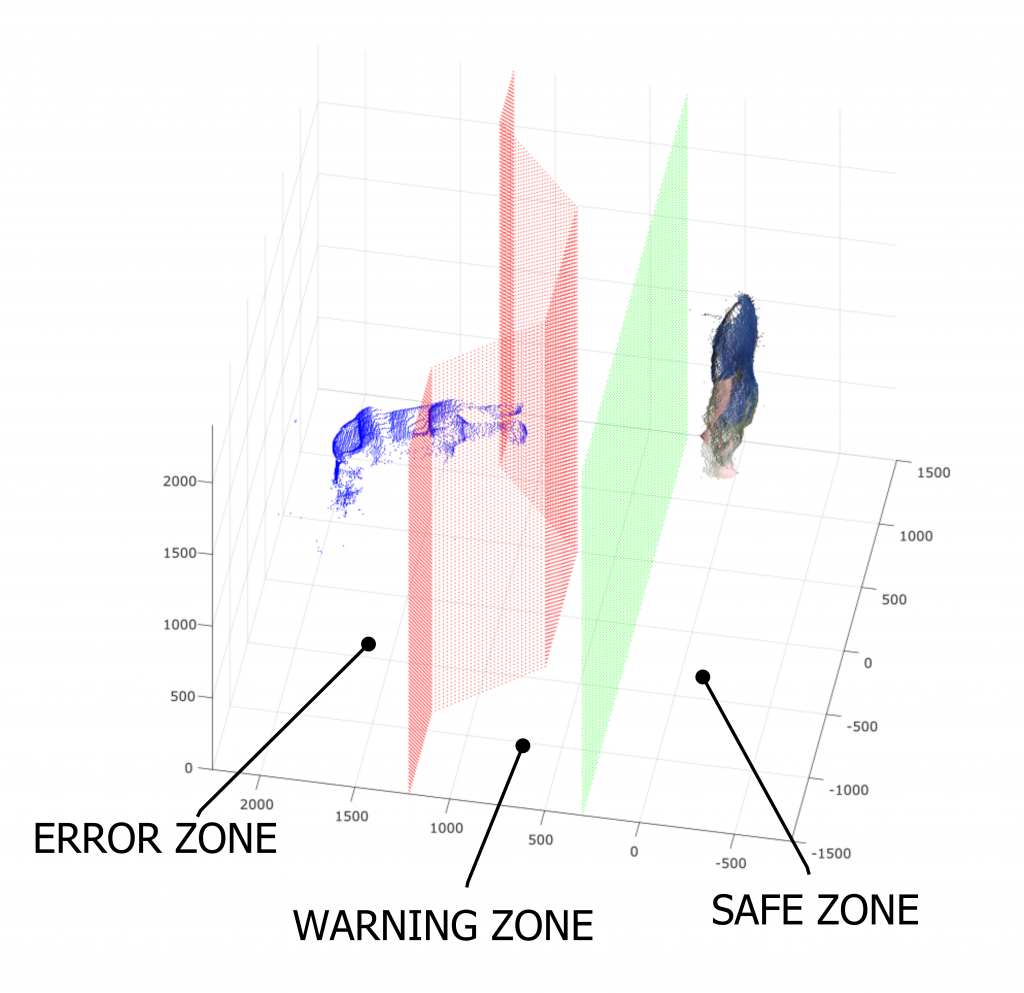
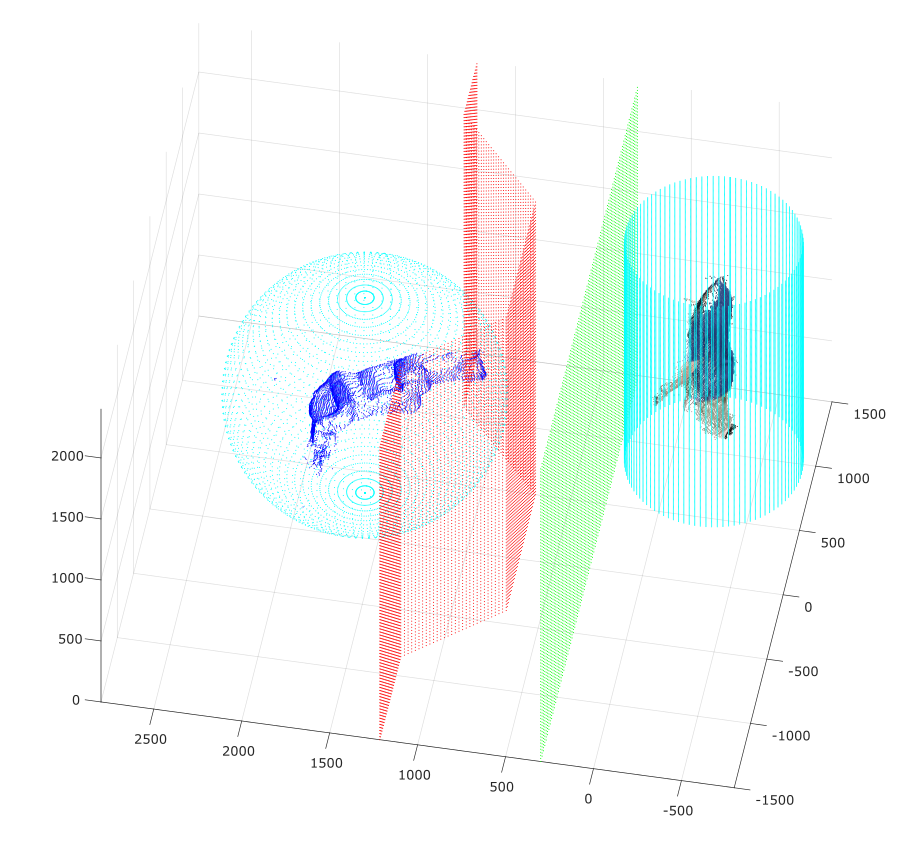
This board is equipped with a GPU, thus allowing a representation in floating point. Even if the FP32 representation is supported, we choose to perform a quantization procedure to reduce the representation complexity of the trained model to a FP16 representation. This choice was driven by the fact that the performances obtained with this representation are considered the best ones by the literature.
The FPGA do not support floating point representations. The toolbox used to modify the original model and adapt it for the board is a proprietary one, called DNNDK.
Two configurations were tested: a configuration where the original model was quantized from FP32 to INT8, thus losing the floating point and critically reduce the dimension of the network to few MB. The average accuracy obtained in this case is 86.6%, slightly better than the baseline probably because of the big representation gap, which in some cases lead to correct predictions the ones that were borderline between correct and incorrect.
The second configuration applies a pruning process after the quantization procedure, thus deleting useless layers. In this case the average accuracy reached is of 84.2%, as expected after the combination of both processes.
STEP 4: Performance benchmark of the boards
Finally we compared the performances obtained by the two boards when running inference in real-time. The results can be found in the presentation below: if you’re interested, feel free to download it!
The thesis document is also available on request.