The tasks of the Barman are summarized here:
- to survey the foreground and check if empty glasses are present;
- to rotate the table and move glasses to the background;
- to monitor for a bottle on the conveyor, recognize it, pick it up, uncork it and fill the glasses;
- to rotate the table to move glasses to the foreground zone.
These simple operations require that suitable image processing is developed and validated. The software environment is the Halcon Library 9.0; the whole-project is deveoped in VB2005. The robot platform is the ORiN 2 (from DENSO).
The work performed so far implements the following basic functions described below.
Calibration of BOTH cameras and robot
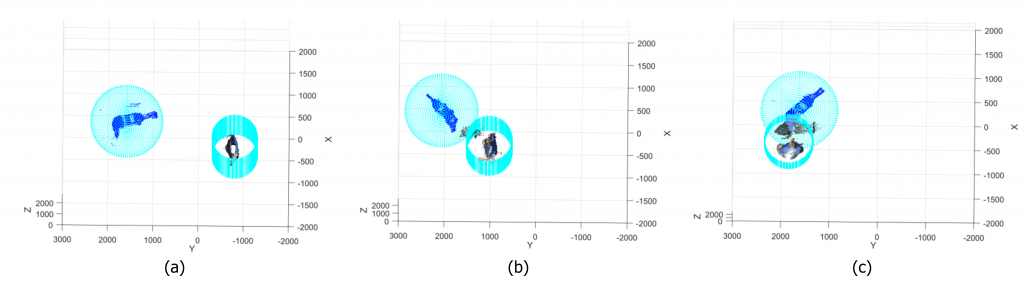
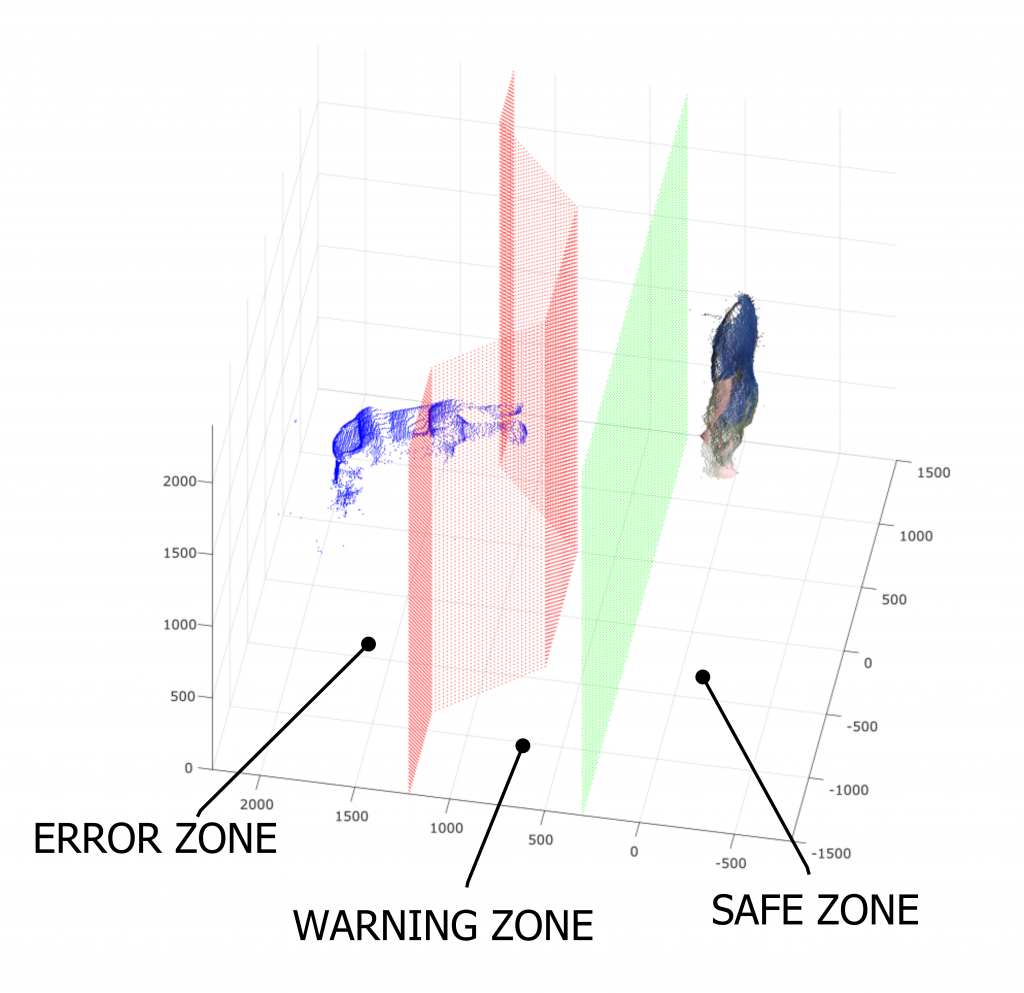
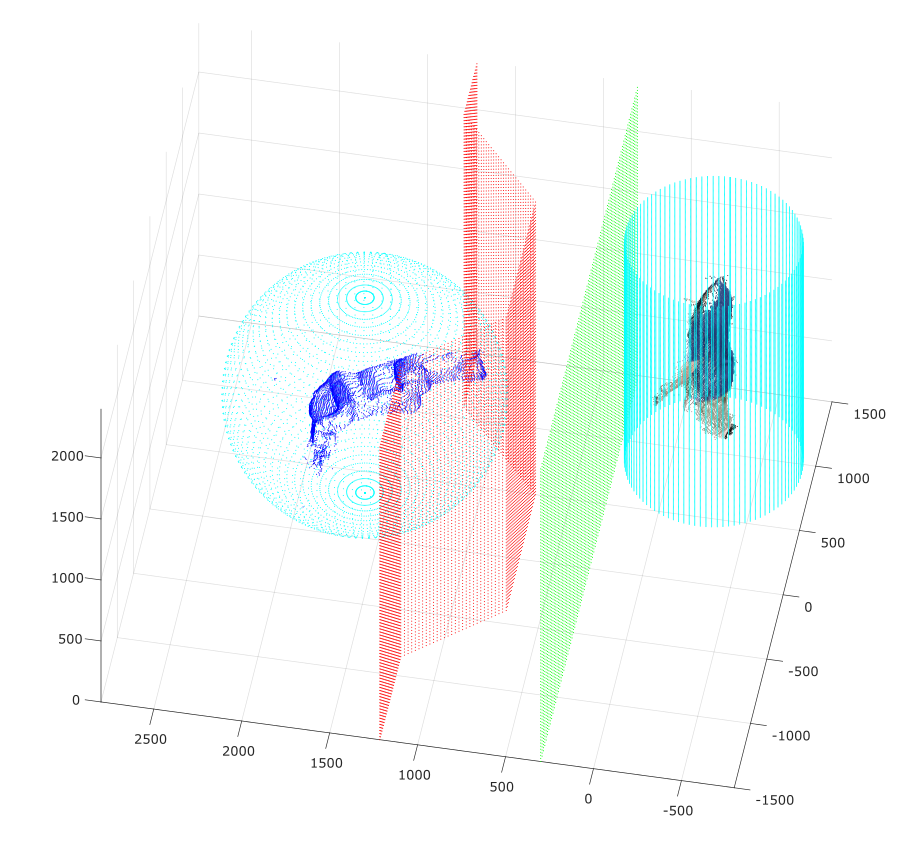
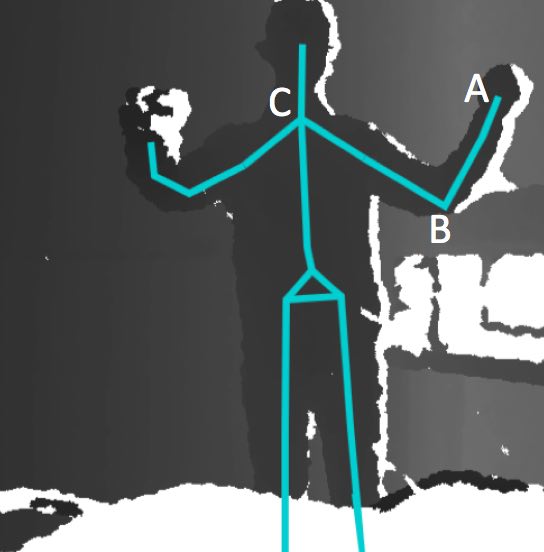
The aim is to define an absolute reference system for space point coordinates, where the camera coordinates can be mapped to the robot coordinates and viceversa. To perform this task a predefined master is used acquired under different perspectives (see Fig. 1 and Fig. 2 ).
The acquired images are elaborated by the Halcon calibration functions, and both extrinsic and intrinsic camera parameters are estimated. In parallel, special procedures for robot calibration have been reproduced and combined with the parameters estimated for the cameras (Fig 3).